
大阪国際工科専門職大学 情報工学科4年 実習生:北野賢一郎
自己紹介
こんにちは!私はフィリンピンと日本のハーフの北野です!
スリーアップ・テクノロジーのブログ記事をよく見ている人なら、
”いやぁ!また、お前かよ!”ってなったかと思います。
今回は4回生になって、スリーアップ・テクノロジーに帰ってきました😊
さらに今回は挑戦的なテーマ、
世界の最先端技術”OpenVLA”に 挑みたいと思います。
※2024年 7月の記事です。
将来、起業を考えており、スリーアップ・テクノロジーさんのところなら
何かヒントになるのではないかと思い、
実習先に決めさせていただきました!!

そもそも、OpenVLAって何??🤔🤔
簡単に言うと・・
OpenVLAは、ロボットがカメラで見た情報を理解し、人間の指示に従って動くことができる技術です!
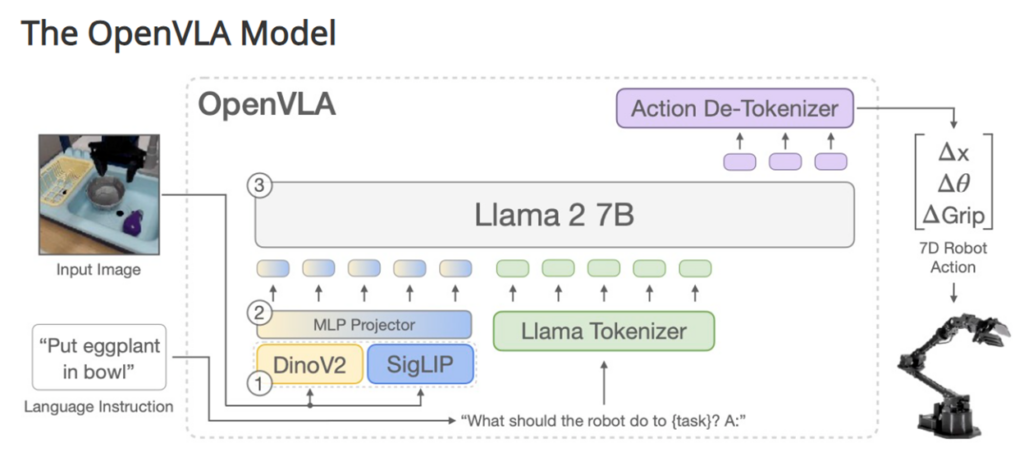
OpenVLAの概要
視覚・言語・行動の統合
OpenVLAは、視覚(ビジョン)、言語、アクション(行動)を統合し、ロボットが複雑なタスクを実行できるように設計されています。
大規模なデータセット
97万件以上のロボットエピソードで訓練されており、多様な状況に対応するロボット操作を実現しています。
モデルの構造
Llama 2 7Bパラメータモデルを基盤とし、視覚エンコーダとしてDINOv2とSigLIPを使用しています。これにより、高精度な視覚情報処理と行動選択ができます。
オープンソース
OpenVLAは完全にオープンソースであり、モデルのチェックポイントやPyTorchのトレーニングパイプラインが公開されています。これにより、研究者や開発者が自由に利用・カスタマイズできます。
詳細はこちら→ OpenVLA https://openvla.github.io/
これをDENSO製垂直多関節ロボットを使用して、実際に動かしてみたい!!ファインチューニングが必要!
開発の取り組み🔧
では、取り組みに説明します!開発はわくわくしますね😁
システム設計図
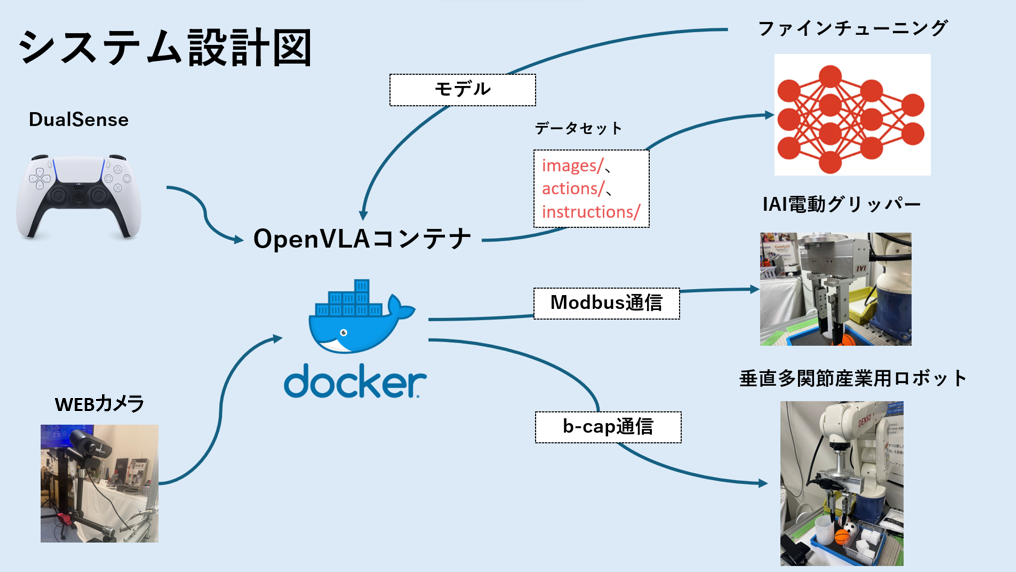
ロボット:垂直多関節産業用ロボットVP-6242を使用します。
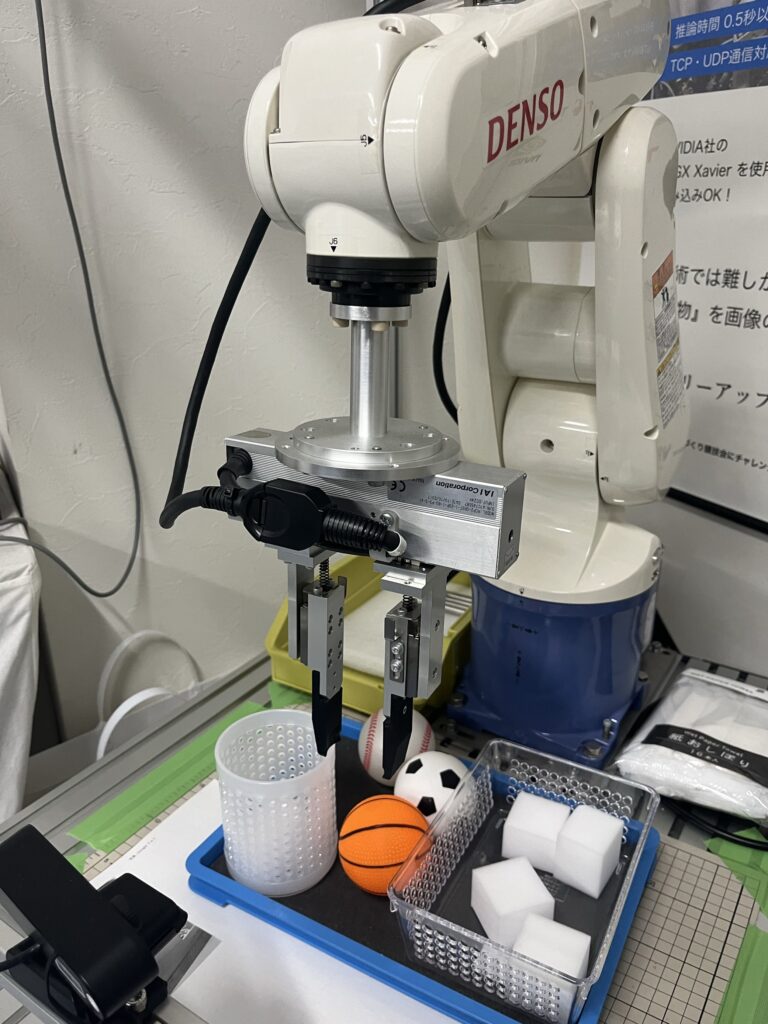
グリッパー:IAI電動グリッパー(RCP2-GRST-I-20P-1-80-P3-S-A1)で物体を操作します。

DualSense:SONYのDUAL SENSEゲームコントローラーをBluetoothで接続し、ユーザーがロボットを制御します。

GPU: NVIDIA TUF-RTX4090-24G-GAMING
メモリ: 128GB (CMN64GX4M2Z3200C16)
OS: Ubuntu Desktop 22.04 LTS
OpenVLAコンテナ:Ubuntu 22.04ベースのコンテナで、CUDA環境で高速推論を行います。
- b-CAP通信:ロボットとのリアルタイム通信で位置・姿勢データを送信。
- Modbus通信(IAIグリッパー):Modbus通信を使用してIAI電動グリッパーの操作を行います。
- カメラ接続:Realsense D415カメラから映像データを取得。
- Bluetooth接続:DualSenseコントローラーからの操作指示を受け取ります。
ファインチューニング:画像データ、行動データ、ユーザープロンプトを用いてモデルの精度を向上させます。
ファインチューニングのためのデータ収集📚
ロボットアームをジョイスティックで操作し、 アクションデータ、カメラ画像、命令文を記録するプログラムを作成しました!
データセットのディレクトリ構造を以下のようにします。
dataset/
├── images/
│ ├── 0.png
│ ├── 1.png
│ └── …
├── actions/
│ ├── 0.csv
│ ├── 1.csv
│ └── …
└── instructions/
├── 0.txt
├── 1.txt
└── …
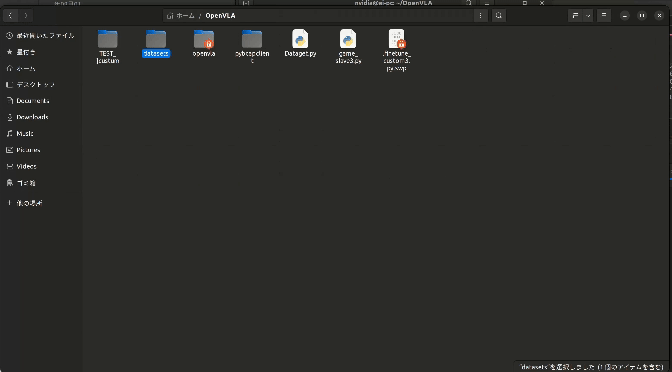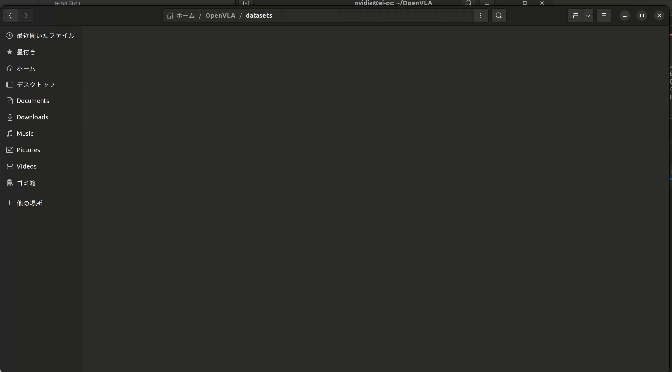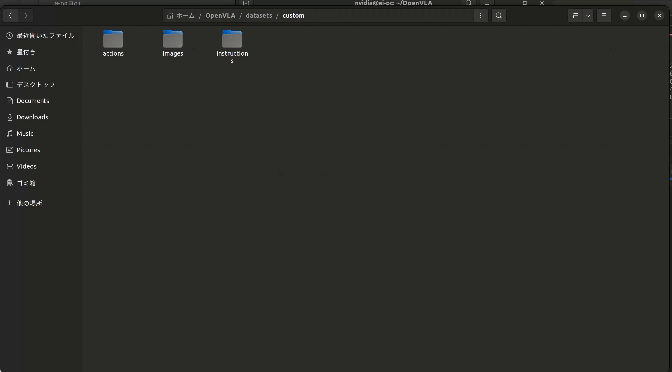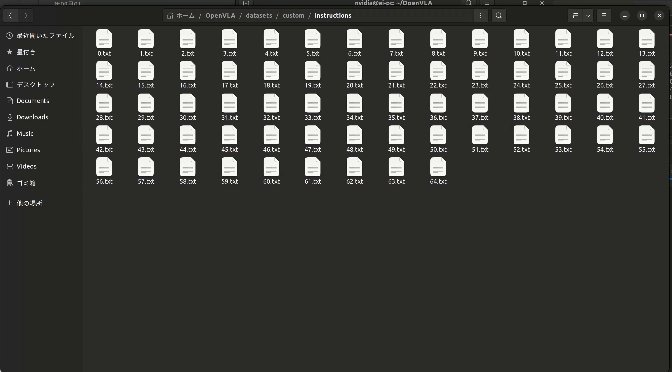
images/: カメラで取得した224×224ピクセルの画像を保存。
actions/: ロボットの動作データ(アクション)をCSV形式で保存。
instructions/: 操作に関する命令文をテキスト形式で保存。
保存手順概要
データの収集:
- ジョイスティックを使用してロボットアームとグリッパーを操作。データ収集は、ユーザーが△ボタンを押すことで開始または停止。
- カメラで取得した画像、ジョイスティックの状態から得られたアクションデータ、および操作時の命令文をそれぞれのディレクトリに保存。
- △ボタンを押すことで、データ記録の開始・停止を切り替え。
- □ボタンが押されると、プログラムは終了。
- 記録開始時にユーザーから命令文を入力してもらい、その内容もデータとして保存。take the soccer ball など。
ポイント💡
データ収集頻度: プログラムはロボット動作時、0.2秒間隔でデータを記録し、5Hzの頻度でジョイスティックの状態とカメラ画像を取得しています!
※右の図はロボットの動作に応じて、自動でimagesが保存されている様子。
図にはありませんが、アクションデータ、命令文も同様に保存されていってます📝

ファインチューニングと推論🖥️
結論からいいますと…
ファインチューニング後のモデルを用いて推論まで行いましたが、望ましい数値が得られず、実習期間中に目標を達成することはできませんでした😓😓😓
推論がうまくいかなかった考察
OpenVLAは、スタンフォード大学のような開発環境で、時間をかけて学習と調整が行われています。
こうした環境での取り組みに比べて、異なる環境でのLoRAによる追加学習は、
実際にはあまり行われていないと考えられます。そのため、精度が十分に出なかったことが一因であると考えられます。
ファインチューニング後のモデルを用いてリアルタイムで推論を行ったものの、予測されたアクションと実際の動作の間にギャップがあり、期待した成果を得ることができませんでした😭
実習のまとめ
この実習では、世界最先端の技術である
OpenVLAを用いて産業用ロボットを制御するという自分にとって難しい課題に取り組みました。ネット上の情報が少なく、ChatGPTのようなAIツールも十分に理解していない状況でのスタートでした。結果的には、うごきませんでしたが、この挑戦を通して多くのことを学びました。
特に、このような課題に直面したときに重要なのは、突破力だと学びました。新しい技術に対して積極的に取り組み、困難を乗り越える力を身に付けることができたと感じています。この経験を通じて、難しい課題に取り組む耐性ができ、未知の領域への挑戦がさらに楽しみになりました😁
また、技術の進化は国内外問わずグローバルに広がっているため、海外の動向にも目を向ける必要性を強く感じました。
これからは、国内だけでなく海外の情報も積極的に取り入れ、新しい技術に柔軟に対応していきたいと思います。
さらに、今回の実習を通じて、産業用ロボットでの
データ収集や新たなマルチモーダルAIを活用した環境を構築することができました。
これにより、どんな新しい技術にも適応できる準備が整ったと思っています。
最後に、この挑戦を支えてくださった
スリーアップ・テクノロジー 三上さん、
今回も本当にありがとうございました。
今回もレベルが上がったのは間違いないです。今後もさらに技術を磨き、次のステップに進んでいきたいと思います。

突破力を武器に、 新たなチャレンジを続けていきます!!
諦めたら試合終了。